The case against automatic marshalling
I've been meaning to write this post for a very, very long time but I guess it was the look I got yesterday in a meeting when I recommended against automatically marshalling JAXB annotated model objects that pushed me over the edge. It was a look of "why would you even consider doing anything else?".
The notion that I can add a few annotations to my domain model class, make that the return type from my web service method and, viola, JSON or XML is magically returned to the client is very enticing. And you can certainly understand why developers would be motivated to want to do that.
But I'd like to offer some food for thought on why that might not be such a good idea and why architects, designers, those having to maintain the system and whoever's paying the bills should consider not allowing this approach in all but proof of concept or prototyping situations.
The first two problems, which are also the most significant, are very closely related:
Problem #1 : The
inability to produce different representations from the same object model. I'm not talking about JSON vs. XML here (i.e. format). I'm talking about content and structure. You can only have one return type from a method and you can only mark up a given model class with annotations in one way. So, let's say you have client A that wants the full object representation returned - you're fine. But what if you have a client B that needs a different representation of that object? Perhaps fewer fields or abbreviated attribute names or some other subset of the object. You can't do it with automatic marshalling and use the same endpoint and without bloating the object model. See
this article for some ideas on how to produce multiple different representations from the same object model.
Problem #2 : The
inability to support multiple versions of the REST contract off of the same object model. This one has the same root cause as above but a different use case for getting there. In this case I'm referring to changes to the object model that cause existing clients to break - breaking changes. In this case you can't simply reuse the same model class to support two incompatible representations of it - you have to create or extend a new model class. But, if you simply decoupled the REST response from your object model (i.e. don't use JAXB annotations and automatic marshalling) you can vary them independently and support multiple versions of your REST contract from the same object model - or at least you have the possibility of doing that, depending on the nature and extent of the changes. Or, even simpler, maybe it's the REST contract itself that's changing (different attribute names, different structure, exposing fewer data elements due to a removed business feature, etc. etc.). Auto marshalling can't expose two different contracts off the same object model.
Either one of those should be enough to discourage folks from using automatic marshalling in most cases, but there are still more reasons to avoid this approach...
Problem #3 : Your REST contract, and therefore your client, is
tightly coupled to your domain/object model. You've basically opened up a window into the deep internals of your system and are allowing clients to peer into it. Some folks try to get around this by creating a secondary model object layer - a data transfer object layer, if you will - but they're still tighly coupled to a particular instance of a particular object model, they've bloated the overall object model, and they've greatly increased the object count at runtime.
Problem #4 : You
lose control of the HTTP response and you won't have an opportunity to catch or log what just happened if there is a problem marshalling or unmarshalling your object. In this case, the framework generates the exception and resulting response to the client - not your code - which is probably something you don't want to have happen.
Problem #5 : This is a consequence of attribute annotations in general in that they
couple the classes being annotated to a particular use, albeit perhaps only logically. But, the implications of doing this can manifest themselves in very concrete ways. Let's say, for example, that RESTful representations and JMS messages are being created from the same model and let's say that the structure of the REST representation and the JMS message are different. OK, so you JAXB annotate the model classes for the REST layer and then the messaging team handcrafts the JMS messages from the same model - that will work and everything is fine. But, what if the messaging team needs to change the model layer to support some new changes to messaging and let's say these changes are breaking changes to the REST layer. Oops. This is really a variation of problems 1 and 2 above. Putting aside this contrived example, the key difference here is that we're introducing another developer (messaging team) who is unaware that the object model they are using in a loosely coupled manner has been tightly coupled by the web services team to their clients (changes to the model classes percolate all the way down to the REST clients).
Problem #6 :
Clarity. When you look at the web service class it's unclear precisely what's being returned and in what format. Sure, you can see what object type it is, and you can look that up and examine it, but changes to the model will go unnoticed when looking at the web service. You should be able to look at your web service class and see the entire contract that your service is providing.
Problem #7 :
The ability to fully enforce the REST contract. Since changes to the model pass straight thru the web service layer you can't enforce the resource representation aspects of the REST contract. However, if you decouple the model from the representation being returned (i.e. hand build the response) you have complete control over the contract.
Problem #8 :
Reduced ability to refactor the service and domain layers. Because the client is tightly coupled to the model you lose the ability to independently vary the model and thus are limited in your ability to refactor the system in a way that preserves the REST contract with existing clients.
Problem #9 :
Extensibility of the REST contract. This is a variation of #1 and #2, but from a different perspective. If using auto marshalling you can't provide a different REST contract to different clients using the same underlying model. Nor could you extend the contract to another system that makes use of auto marshalling (perhaps you want to use the adapter pattern on an inherited system to make it appear to have the same interface as yours - a consideration for growing and expanding companies and the kind of things architects are tasked with worrying about and considering).
Problem #10 :
Lack of flexibility. By using auto marshalling you lose the ability to compose a composite resource representation from multiple top-level objects. In addition, nested hierarchies may or may not behave the way we necessarily want with auto marshalling.
Problem #11 :
Time Savings. It's not a tremendous coding time saver - not enough to justify introducing all the other problems mentioned here, despite what people may think. It takes very little effort to code up a JSONObject or an XML document and just a little bit more to create a generic abstraction layer on top of that so you can produce JSON or XML or whatever.
Problem #12 :
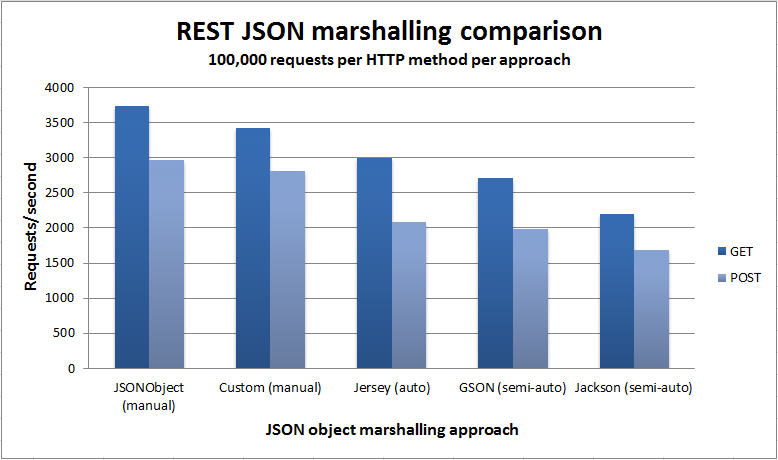
Performance. I decided to take a closer look at the performance of various approaches for sending and receiving JSON representations to/from a RESTful web service. I used the Jersey Test Framework to create a unit test that invoked the handler methods to GET and POST JSON data to/from the same underlying model object. The only difference was the approach used to map the JSON to/from the underlying object. The object itself consisted of a String field and a couple of int fields (see below).
The test iterated over each approach in a round robin fashion performing a GET and a POST. That cycle was repeated 100,000 times. The metrics were captured in the unit test client, encompassing the entire request/response. Here are the approaches that were evaluated:
- Manually building the response using org.codehaus.jettison.json.JSONObject (ver 1.1)
- Manually building the response using a custom implementation using StringBuilder (Java 1.7)
- Automatic marshalling using the Jersey framework (ver 1.17) and underlying JAXB implementation
- Instructing a com.google.gson.Gson (ver 2.2.2) instance to map an object to JSON for us
- Instructing a org.codehaus.jackson.map.ObjectMapper (ver 1.9.2) instance to map for us
As you can see from the chart below, the
manual approaches to handling the JSON/object mapping were quite a bit better performing, and that makes sense as they don't have to use reflection to access the object and build up the response. What was interesting was just how much better performing the manual approaches were. That may or not be an important consideration depending on your situation, but it's information you should be armed with nonetheless and I encourage you to perform your own testing to see for yourself. The best I can tell here is that the margin of error is about 5% as both manual approaches used the same POST handler yet the results for them differ by about 5%. So, again, conduct your own tests in your own environment to see how the numbers shake out for you.
 |
| Marshalling Performance Comparison |
Here's the interesting code from the web service showing the different approaches used. First is a complete POST handler. Each POST implementation is the same except for the mechanism used to turn the data into an ItemInventory object. I used custom media types to map to the various handlers, reusing the same URL/endpoint and in effect versioning the service.
Jersey :
@Path("/item")
@Consumes(ITEM_INVENTORY_MEDIA_TYPE_JERSEY_JSON)
@POST
public Response createItemInventory2(ItemInventory inventory) {
Response response = null;
try {
inventory = _inventoryManager.saveItemInventory(inventory);
response = Response.status(201)
.header(
"Location",
String.format(
"%s/%s",
_uriInfo.getAbsolutePath().toString(),
inventory.getItemId()
)
)
.entity(inventory.getItemId())
.build();
} catch (Exception e) {
response = Response.status(500).entity(e.getMessage()).build();
}
return response;
} // createItemInventory()
org.codehaus.jackson.map.ObjectMapper:
@Path("/item")
@Consumes(ITEM_INVENTORY_MEDIA_TYPE_JACKSON_JSON)
@POST
public Response createItemInventory3(String data) {
Response response = null;
try {
ItemInventory inventory = new ObjectMapper().readValue(data, ItemInventory.class);
inventory = _inventoryManager.saveItemInventory(inventory);
com.google.gson.Gson:
@Path("/item")
@Consumes(ITEM_INVENTORY_MEDIA_TYPE_GSON_JSON)
@POST
public Response createItemInventory5(String data) {
Response response = null;
try {
Gson gson = new Gson();
ItemInventory inventory = gson.fromJson(data, ItemInventory.class);
inventory = _inventoryManager.saveItemInventory(inventory);
JSONObject (for the POST I did not write a custom handler, but instead used JSONObject):
@Path("/item")
@Consumes({
ITEM_INVENTORY_MEDIA_TYPE_JSONOBJECT_JSON,
ITEM_INVENTORY_MEDIA_TYPE_CUSTOM_JSON
})
@POST
public Response createItemInventory(String data) {
Response response = null;
try {
ItemInventory inventory = jsonObjectToItemInventory(data);
inventory = _inventoryManager.saveItemInventory(inventory);
...
private ItemInventory jsonObjectToItemInventory(String data)
throws JSONException {
JSONObject jo = new JSONObject(data);
ItemInventory inventory = new ItemInventory(
jo.isNull("id") ? null : jo.getString("id"),
jo.getInt("onhand"),
jo.getInt("onOrder")
);
return inventory;
} // jsonObjectToItemInventory()
Now for a complete GET handler, this time for
Jersey:
@Path("/item/{itemId}")
@Produces(ITEM_INVENTORY_MEDIA_TYPE_JERSEY_JSON)
@GET
public ItemInventory getItemInventory2(@PathParam("itemId") String itemId) {
ItemInventory inv = null;
try {
inv = _inventoryManager.getItemInventory(itemId);
if (null == inv) {
throw new WebApplicationException(404);
}
} catch (Exception e) {
throw new WebApplicationException(e, 500);
}
return inv;
} // getItemInventory2()
org.codehaus.jackson.map.ObjectMapper:
@Path("/item/{itemId}")
@Produces(ITEM_INVENTORY_MEDIA_TYPE_JACKSON_JSON)
@GET
public Response getItemInventory3(@PathParam("itemId") String itemId) {
Response response = null;
try {
ItemInventory inv = _inventoryManager.getItemInventory(itemId);
if (null == inv) {
// not found
response = Response.status(404).build();
} else {
String json = new ObjectMapper().writeValueAsString(inv);
response = Response.ok().entity(json).build();
}
com.google.gson.Gson:
@Path("/item/{itemId}")
@Produces(ITEM_INVENTORY_MEDIA_TYPE_GSON_JSON)
@GET
public Response getItemInventory5(@PathParam("itemId") String itemId) {
Response response = null;
try {
ItemInventory inv = _inventoryManager.getItemInventory(itemId);
if (null == inv) {
// not found
response = Response.status(404).build();
} else {
Gson gson = new Gson();
response = Response.ok().entity(gson.toJson(inv)).build();
JSONObject:
@Path("/item/{itemId}")
@Produces(ITEM_INVENTORY_MEDIA_TYPE_JSONOBJECT_JSON)
@GET
public Response getItemInventory(@PathParam("itemId") String itemId) {
Response response = null;
try {
ItemInventory inv = _inventoryManager.getItemInventory(itemId);
if (null == inv) {
// not found
response = Response.status(404).build();
} else {
JSONObject jo = new JSONObject();
jo.put("id", inv.getItemId());
jo.put("onhand", inv.getOnhand());
jo.put("onOrder", inv.getOnOrder());
response = Response.ok().entity(jo.toString()).build();
}
And finally the
custom handler. JsonBuilder is my own helper class that provides JSON formatting and uses a StringBuilder internally:
@Path("/item/{itemId}")
@Produces(ITEM_INVENTORY_MEDIA_TYPE_CUSTOM_JSON)
@GET
public Response getItemInventory4(@PathParam("itemId") String itemId) {
Response response = null;
try {
ItemInventory inv = _inventoryManager.getItemInventory(itemId);
if (null == inv) {
// not found
response = Response.status(404).build();
} else {
JsonBuilder jb = new JsonBuilder();
jb.beginObject();
jb.addAttribute("id", inv.getItemId());
jb.addAttribute("onhand", inv.getOnhand());
jb.addAttribute("onOrder", inv.getOnOrder());
response = Response.ok().entity(jb.toString()).build();
If you're interested in the custom media types here's what they look like:
public static final String ITEM_INVENTORY_MEDIA_TYPE
= "application/vnd.my-org.item.inventory";
public static final String ITEM_INVENTORY_MEDIA_TYPE_JSONOBJECT_JSON
= ITEM_INVENTORY_MEDIA_TYPE + ".JSONOBJECT+json";
public static final String ITEM_INVENTORY_MEDIA_TYPE_JERSEY_JSON
= ITEM_INVENTORY_MEDIA_TYPE + ".JERSEY+json";
public static final String ITEM_INVENTORY_MEDIA_TYPE_JACKSON_JSON
= ITEM_INVENTORY_MEDIA_TYPE + ".JACKSON+json";
public static final String ITEM_INVENTORY_MEDIA_TYPE_CUSTOM_JSON
= ITEM_INVENTORY_MEDIA_TYPE + ".CUSTOM+json";
public static final String ITEM_INVENTORY_MEDIA_TYPE_GSON_JSON
= ITEM_INVENTORY_MEDIA_TYPE + ".GSON+json";
Here's the JUnit test method used to exercise the above web service handlers:
@Test
public void testCreateVersion2() throws InterruptedException {
int onhand = 35;
int onOrder = 3;
int iterations = 100000;
JSONObject resource = new JSONObject();
try {
String[] mediaTypes = {
InventoryWebService.ITEM_INVENTORY_MEDIA_TYPE_CUSTOM_JSON,
InventoryWebService.ITEM_INVENTORY_MEDIA_TYPE_JSONOBJECT_JSON,
InventoryWebService.ITEM_INVENTORY_MEDIA_TYPE_JACKSON_JSON,
InventoryWebService.ITEM_INVENTORY_MEDIA_TYPE_JERSEY_JSON,
InventoryWebService.ITEM_INVENTORY_MEDIA_TYPE_GSON_JSON
};
long[][] timers = { {0, 0, 0, 0, 0}, {0, 0, 0, 0, 0} };
// get the plumbing working 1st time
WrappedClientResponse response = post(
"/inventory/item",
mediaTypes[0],
resource.toString()
);
for (int i = 0; i < iterations; i++) {
for (int j = 0; j < mediaTypes.length; j++) {
resource.remove("id");
resource.remove("itemId");
resource.put("onhand", onhand);
resource.put("onOrder", onOrder);
response = post(
"/inventory/item",
mediaTypes[j],
resource.toString()
);
timers[TIMER_POST][j] += response.getResponseTime();
assertEquals(201, response.getStatus());
assertNotNull(response.getHeaders().get("Location"));
String itemId = response.getEntity(String.class);
// now check to make sure we can fetch the item we just created
response = get(
String.format("/inventory/item/%s", itemId),
mediaTypes[j]
);
timers[TIMER_GET][j] += response.getResponseTime();
assertEquals(200, response.getStatus());
resource = new JSONObject(response.getEntity(String.class));
assertEquals(35, resource.getInt("onhand"));
assertEquals(3, resource.getInt("onOrder"));
} // for
}
showStats(iterations, timers, mediaTypes);
} catch (JSONException e) {
fail(e.getMessage());
}
Thread.sleep(1000);
} // testCreateVersion2()
Here are the convenience methods used by the tests to execute the HTTP requests and capture the metrics:
protected WrappedClientResponse get(String uri, String mediaType) {
if (StringUtils.isEmpty(uri) || StringUtils.isEmpty(mediaType)) {
throw new IllegalArgumentException("Programming error - required param missing");
}
WebResource resource = resource().path(uri);
WebResource.Builder builder = resource.accept(mediaType);
long start = System.currentTimeMillis();
ClientResponse response = builder.get(ClientResponse.class);
long stop = System.currentTimeMillis();
WrappedClientResponse wrappedResponse = new WrappedClientResponse(response, stop - start);
trace(response);
return wrappedResponse;
} // get()
protected WrappedClientResponse post(String uri, String mediaType, String data) {
if (StringUtils.isEmpty(uri) || StringUtils.isEmpty(mediaType) || StringUtils.isEmpty(data)) {
throw new IllegalArgumentException("Programming error - required param missing");
}
WebResource resource = resource().path(uri);
WebResource.Builder builder = resource.header("Content-Type", mediaType);
long start = System.currentTimeMillis();
ClientResponse response = builder.post(ClientResponse.class, data);
long stop = System.currentTimeMillis();
WrappedClientResponse wrappedResponse = new WrappedClientResponse(response, stop - start);
trace(response);
return wrappedResponse;
} // post()
Here's the model class used for the testing:
@XmlRootElement
public class ItemInventory {
private static final long serialVersionUID = -4142709485529021223L;
// item ID
@SerializedName("itemId")
private String _itemId;
public String getItemId() { return _itemId; }
public void setItemId(String itemId) { _itemId = itemId; }
// onhand
@SerializedName("onhand")
private int _onhand;
public int getOnhand() { return _onhand; }
public void setOnhand(int onhand) { _onhand = onhand; }
// on order
@SerializedName("onOrder")
private int _onOrder;
public int getOnOrder() { return _onOrder; }
public void setOnOrder(int onOrder) { _onOrder = onOrder; }
public ItemInventory() {}
public ItemInventory(String itemId, int onhand, int onOrder) {
_itemId = itemId;
_onhand = onhand;
_onOrder = onOrder;
} // constructor
} // class ItemInventory
See
this article to learn more about the Jersey Test Framework.






{kind=link}